"I'm using React and Gatsby as the two main technologies behind this blog." I wrote that in February 2020. A CS student in Dortmund with a freshly deployed Netlify site and a list of posts I was going to write. The site went up. The posts didn't.
Six years later I rebuilt it from scratch. In the gap: a Master's in Enterprise Computing, a few years of production work at adesso SE, and a fairly different understanding of what software development actually involves. Enterprise-scale codebases change how you read code. Working between clients and development teams changes how you think about requirements abd what gets lost in translation, why it gets lost, and what it costs when it does. This site is partly a product of that.
Here's what the rebuild looked like.
What changed in the stack
Gatsby is gone. Next.js with static export covers the same ground. Build-time HTML, zero server requirements with better long-term support and a less opinionated data layer. The React model has also matured meaningfully: React Compiler handles memoization automatically, removing an entire category of manual optimization decisions. Tailwind v4 eliminated its config file; styles live in CSS now, which is where they belonged. The output is identical: a folder of static HTML that deploys anywhere. The tooling to get there is less ceremonial.
None of these are dramatic choices. They're the pragmatic defaults for 2026 which is the point.
Agentic development as a workflow, not a novelty
The more significant change is how the implementation happened.
I used Claude Code throughout the build. Not as autocomplete, and not as a code generator to copy from as an agent I directed through a specification. My role was requirements engineering and review: defining the design system as a structured token set, specifying component behavior and hierarchy in explicit terms, and then evaluating what came back against those requirements.
That last part is where most of the actual work lives. Reviewing generated code is not passive. You're checking whether the implementation matches the spec, identifying where the model made reasonable assumptions that don't hold, and deciding whether to correct the spec or the output. It's closer to a technical review process than to typing code and it demands the same clarity about requirements that good engineering always has.
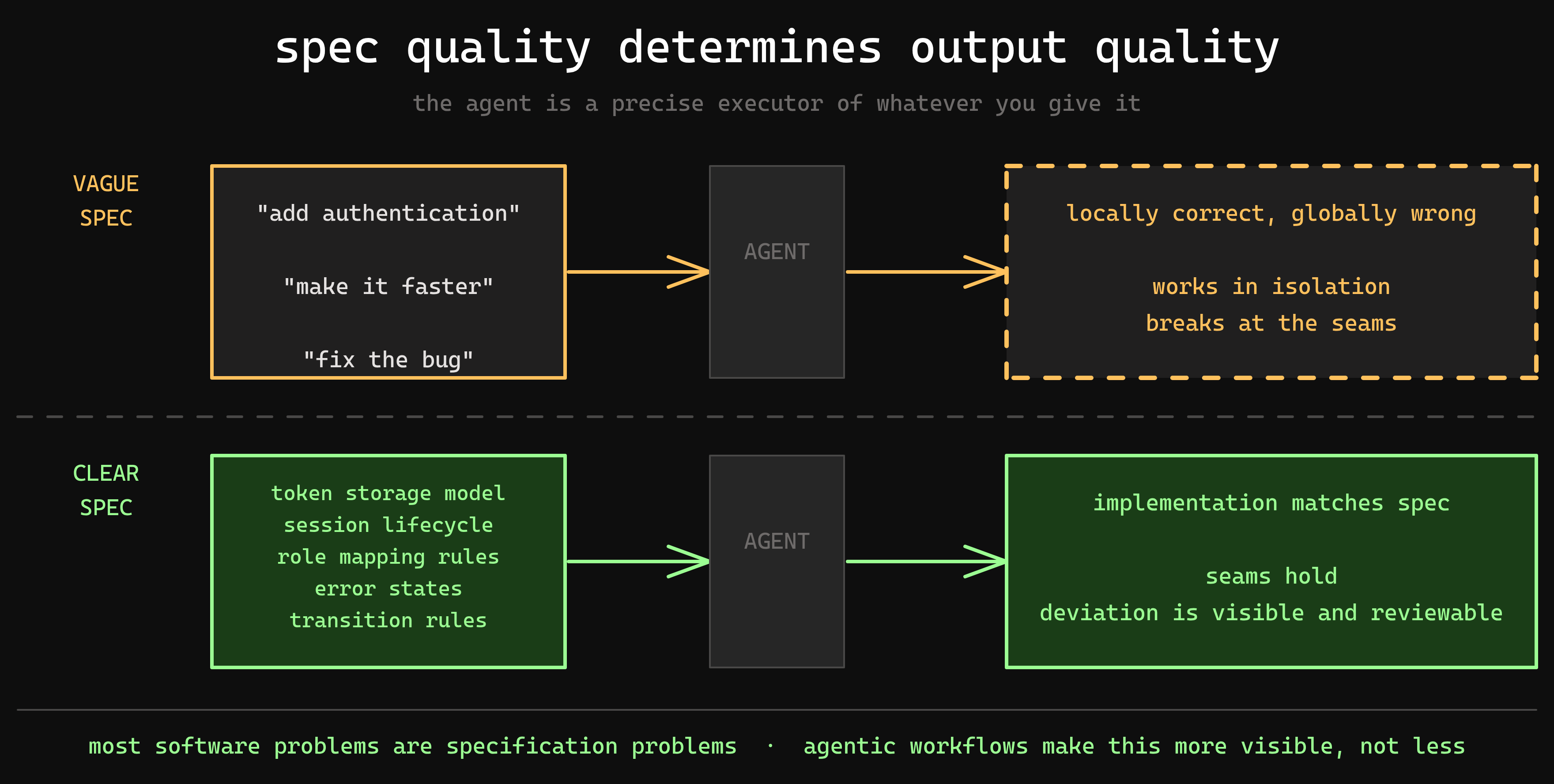
What I found: the quality of the output is entirely determined by the quality of the specification. Vague inputs produce implementations that are locally reasonable and globally wrong. The discipline of writing a clear spec down to transition rules, spacing scales, color semantics is what makes the agent useful rather than just fast. Anyone who has watched a development team build the wrong thing correctly will recognise the failure mode.
Design systems as requirements artifacts
The site runs on a design system I called the Monolith Protocol. Functionally, it's a set of CSS custom properties covering surface colors, typography scale, spacing, and transition rules. Semantically, it's a requirements document that the agent operated against.
A few of the constraints were deliberate: border-radius: 0 enforced globally, transitions limited to either 0ms or 50ms, a phosphor green primary against near-black surfaces. These aren't just aesthetic choices they're rules that the system either satisfies or violates, which makes deviation visible and reviewable.
At work, you inherit the design system or work within whatever constraints the client brings. A personal project is where you can build one properly, from scratch, and actually see where your decisions compound over time. The exercise here was less about the specific choices and more about the discipline of making them explicit and enforcing them consistently.
Where the learning shifted
In 2020, learning by building meant typing code: installing plugins, writing queries, watching things work. Competence was measurable at the keyboard.
In 2026, the agent handles implementation. What it can't handle is architecture. Not in the formal sense, not UML diagrams and enterprise patterns, but the quieter decisions that determine whether a system holds together: where the boundaries between components belong, how state should flow, what belongs in a token and what belongs in a rule, when two constraints conflict which one wins and why.
These are decisions that require a model of the whole system in your head before any code exists. An agent with a weak spec will produce something that works locally and breaks at the seams. The seams are where the architectural thinking lives, and that thinking has to come from the developer.
The same is true at the integration layer, which is where most real systems actually live. Custom code rarely runs in isolation. It runs alongside standard software: ERPs, CMS platforms, identity providers, third-party APIs, each with its own data model, its own failure modes, its own assumptions about who owns what. Integrating these systems through an agentic workflow doesn't make that complexity disappear. It makes the developer's understanding of it more load-bearing. The agent will wire things together exactly as specified. Whether the specification reflects how those systems actually behave in production is a different question entirely, and not one the agent can answer.
That production dimension matters. An architecture that looks correct in isolation can behave unexpectedly under real load, real latency, real data. Understanding why, tracing a failure back through the integration points, knowing which system introduced the inconsistency and why, requires a depth of technical knowledge that no amount of generated code substitutes for. You have to know what the architecture does, not just what it's supposed to do.
What enterprise work teaches you, eventually, is that most software problems are specification problems. The code is usually fine. What's wrong is the model of the problem the code was built against. Agentic workflows make this more visible, not less: the agent is a precise executor of whatever you give it. If what you give it is underspecified, you'll know immediately. If your mental model of the system has gaps, the output will find them.
This is also where continuous improvement becomes a technical discipline rather than a process checkbox. Iterating on a system you built with an agent is fast: adjusting a component, refining a boundary, tightening a constraint. But knowing what to iterate on requires reading the system diagnostically, understanding what the current architecture optimises for, where it creates friction, and what the cost of changing it is. That judgement doesn't come from the agent. It accumulates from building things, watching them run, and being honest about where the original model was wrong.
The skill that matters now isn't typing speed or framework familiarity. It's the ability to hold a system architecture clearly enough to specify it, understand it well enough to integrate it with the systems around it, and stay close enough to production to know when the model needs to change.